Distributed Inference#
Some language models including DeepSeek V3, DeepSeek R1, etc are too large to fit into GPus on a single machine, Xinference supported running these models across multiple machines.
Added in version v1.3.0.
Supported Engines#
Now, Xinference supported below engines to run models across workers.
SGLang (supported in v1.3.0)
vLLM (supported in v1.4.1)
MLX (supported in v1.7.1), MLX distributed currently does not support all models. The following model types are supported at this time. If you have additional requirements, feel free to submit a GitHub issue at xorbitsai/inference#issues to request support.
DeepSeek v3 and R1
Qwen2.5-instruct and the models have the same model architectures.
Qwen3 and the models have the same model architectures.
Qwen3-moe and the models have the same model architectures.
Usage#
First you need at least 2 workers to support distributed inference. Refer to running Xinference in cluster to create a Xinference cluster including supervisor and workers.
Then if are using web UI, choose expected machines for worker count in the optional configurations,
if you are using command line, add --n-worker <machine number> when launching a model.
The model will be launched across multiple workers accordingly.
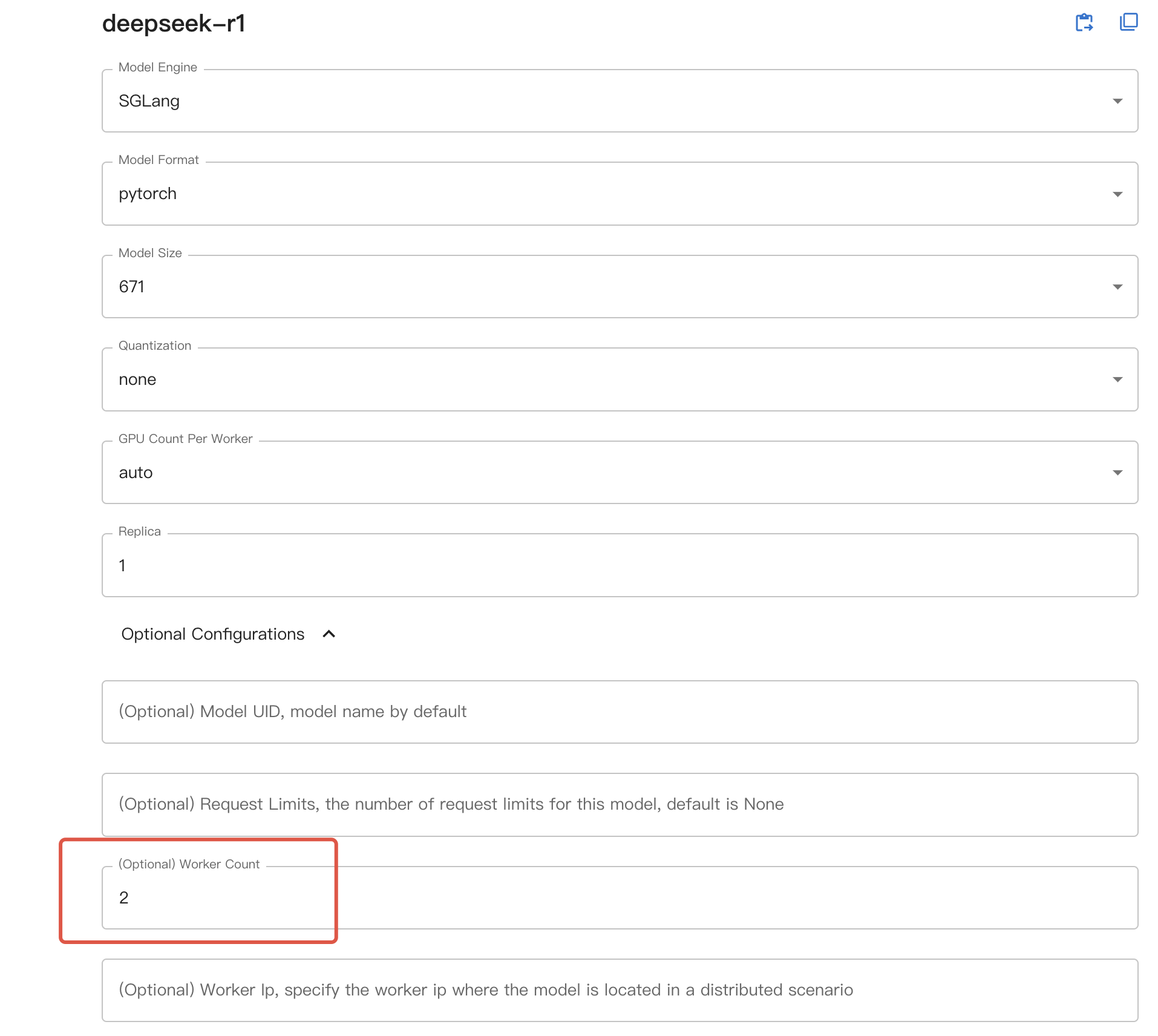
GPU count on web UI, or --n-gpu for command line now mean GPUs count per worker if you are using distributed inference.