分布式推理#
一些语言模型,包括 DeepSeek V3、DeepSeek R1 等,体积过大,无法适配单台机器上的 GPU,Xinference 支持在多台机器上运行这些模型。
备注
这些特性在 v1.3.0 中添加。
支持的引擎#
现在,Xinference 支持如下引擎在多台 worker 上运行模型。
SGLang (在 v1.3.0 中支持)
以下引擎即将支持分布式推理:
使用#
首先,您需要至少 2 个工作节点来支持分布式推理。请参考 在集群中运行 Xinference 以创建包含 supervisor 节点和 worker 节点的 Xinference 集群。
然后,如果您使用的是 Web UI,请在可选配置中选择期望的机器数量作为 worker count;如果您使用的是命令行,启动模型时请添加 --n-worker <机器数量>。模型将相应地在多个工作节点上启动。
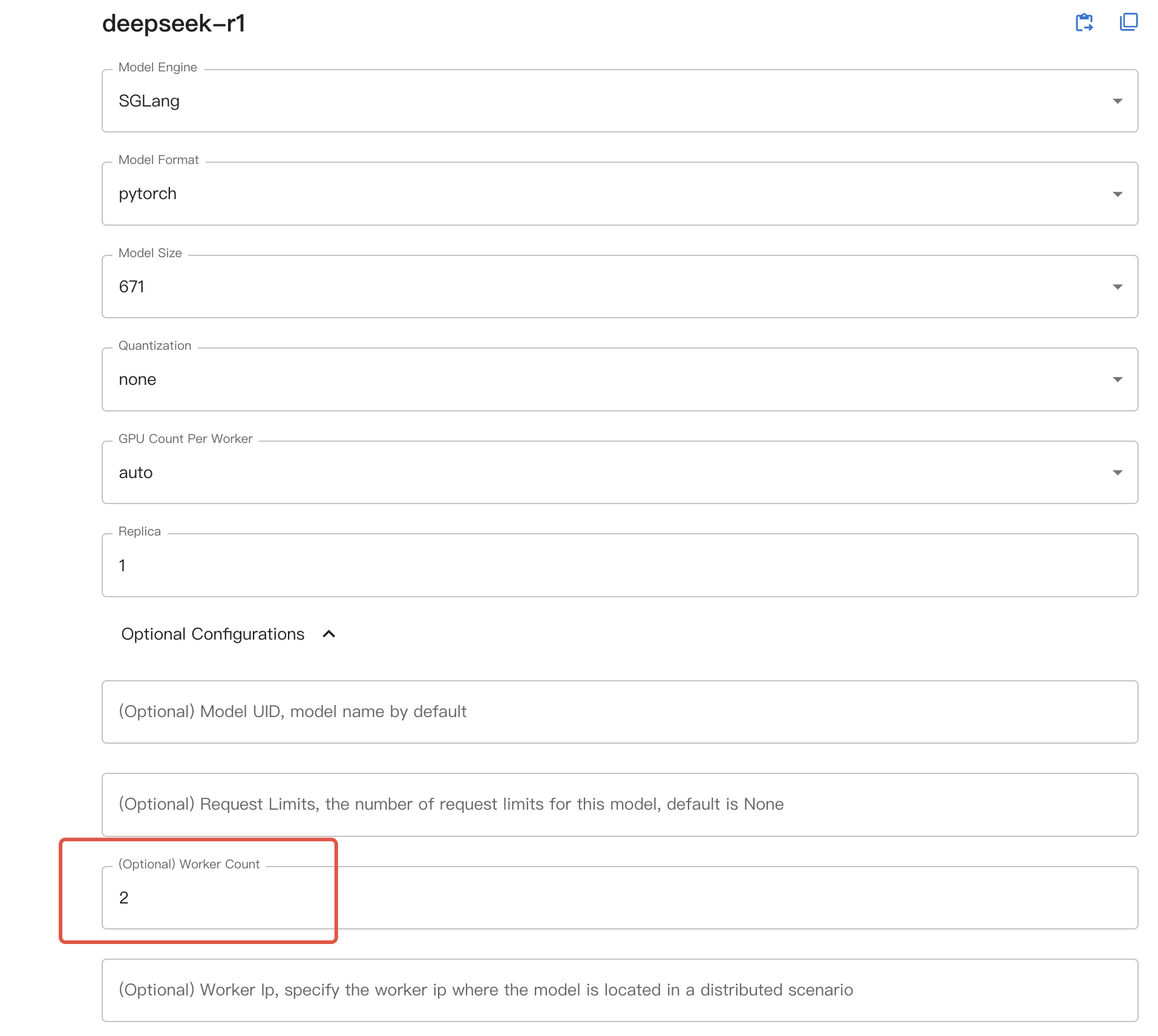
使用分布式推理时,在 Web UI 中的 GPU count 或命令行中的 --n-gpu 现在表示每个工作节点的 GPU 数量。