推理引擎#
Xinference 对于不同模型支持不同的推理引擎。用户选择模型后,Xinference 会自动选择合适的引擎
llama.cpp#
Xinference 目前支持由 Xinference 团队开发的 xllamacpp 作为 llama.cpp 后端运行。llama.cpp 基于张量库 ggml 开发,支持 LLaMA 系列模型及其变体的推理。
警告
自 Xinference v1.5.0 起,xllamacpp 成为 llama.cpp 的默认选项,llama-cpp-python 被弃用;从 Xinference v1.6.0 开始,llama-cpp-python 已被移除。
请参考 llama.cpp 的 common.h 中 common_params 结构体定义设置参数。
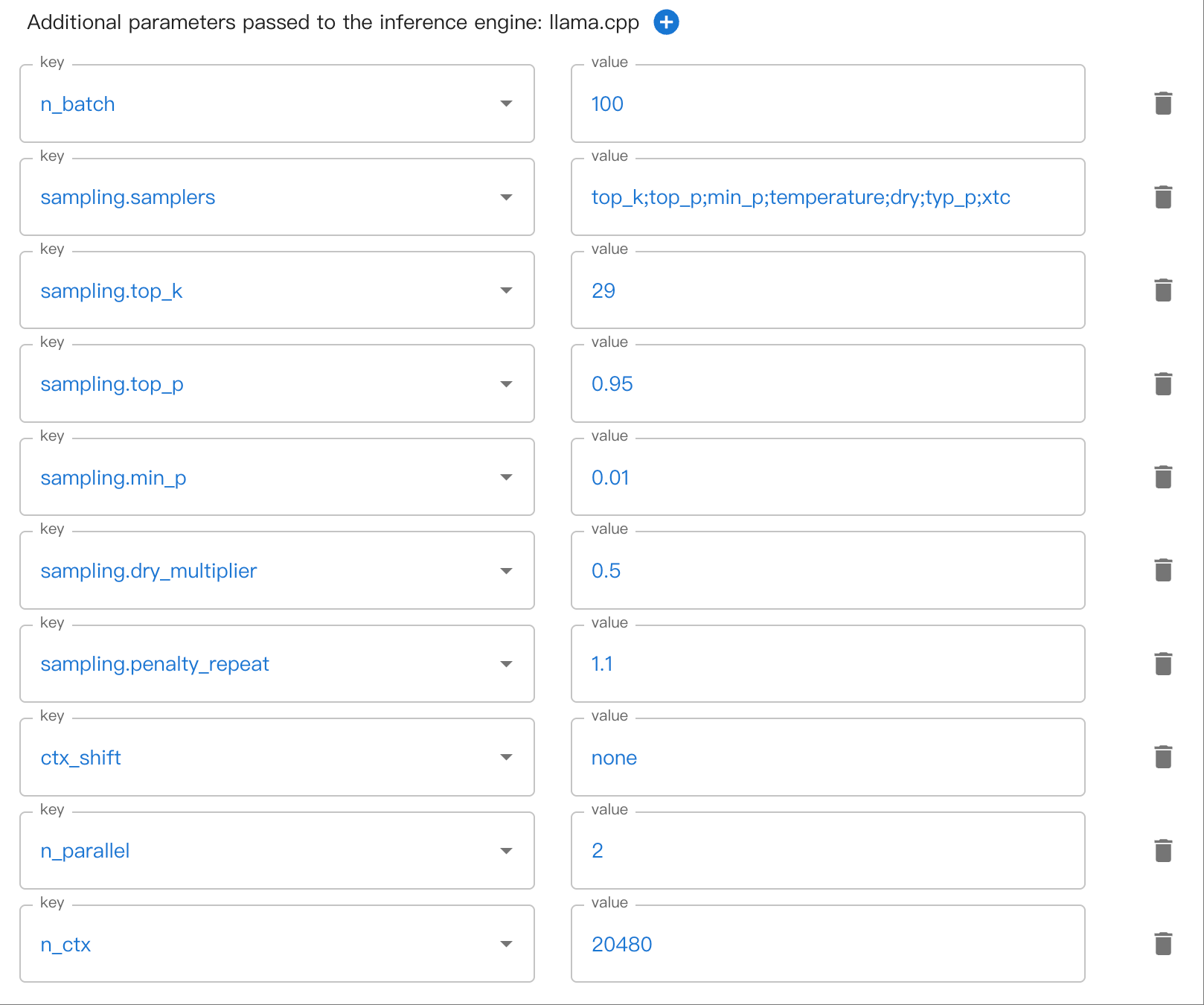
可能会有嵌套多层的参数。例如,sampling.top_k。请使用 . 来分割嵌套参数。
这里有一个在 WebUI 中设置嵌套 sampling 参数的例子:
自动 NGL#
Added in version v1.6.1: 自 v1.6.1 起,当未指定 n-gpu-layers(默认为 -1)时,将自动启用 GPU 层数估算功能。
这个特性可以为 llama.cpp 后端自动设置 GPU 层数(NGL)。请注意这并不是一个精确的计算,因此 -ngl 结果可能不是最优的,并且仍然可能遇到显存不足的错误。
目前自动 NGL 没有官方支持。请参考下面 issue 来了解更多详情:
我们的实现是基于 Ollama 的自动 NGL,但是有一些不同之处:
我们使用 xllamacpp 提供的设备信息。
我们删除了一些不常见的架构支持,这些架构下会使用默认计算逻辑。
如果自动 NGL 失败,我们会尝试全部加载到 GPU。
我们不支持多模态投影器内嵌到模型的 GGUF,这种格式的模型目前还处于实验阶段。
常见问题#
Server error: {'code': 500, 'message': 'failed to process image', 'type': 'server_error'}
服务端日志:
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
可能由于内存不足导致。你可以尝试减小
n_ctx解决。Server error: {'code': 400, 'message': 'the request exceeds the available context size. try increasing the context size or enable context shift', 'type': 'invalid_request_error'}
如果你正在使用 multimodal 功能,
ctx_shift会被默认关闭。请尝试增加n_ctx或者减小n_parallel以增加每个 slot 的 context 大小。Server error: {'code': 500, 'message': 'Input prompt is too big compared to KV size. Please try increasing KV size.', 'type': 'server_error'}
服务端日志:
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
可能由于 KV cache 创建失败导致。你可以通过减小
n_ctx或者增加n_parallel或者调节n_gpu_layers参数加载部分模型到 GPU 来解决。请注意,如果你只处理串行推理请求,增加n_parallel并不会带来性能提升。
transformers#
Transformers 支持绝大部分新出的模型。是 Pytorch 格式模型默认使用的引擎。
vLLM#
vLLM 是一个非常高效并且易用的大语言模型推理引擎。
vLLM 具有以下特点:
领先的推理吞吐量
使用 PagedAttention 高效管理注意力键和值记忆
对传入请求进行连续批处理
优化的 CUDA 内核
当满足以下条件时,Xinference 会自动选择 vLLM 作为推理引擎:
模型格式为
pytorch,gptq,awq,fp4,fp8或者bnb。当模型格式为
pytorch时,量化选项需为none。当模型格式为
awq时,量化选项需为Int4。当模型格式为
gptq时,量化选项需为Int3,Int4或Int8。操作系统为 Linux 并且至少有一个支持 CUDA 的设备
自定义模型的
model_family字段和内置模型的model_name字段在 vLLM 的支持列表中。
目前,支持的模型包括:
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,vibethinker,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang 具有基于 RadixAttention 的高性能推理运行时。它通过在多个调用之间自动重用KV缓存,显著加速了复杂 LLM 程序的执行。它还支持其他常见推理技术,如连续批处理和张量并行处理。
MLX#
MLX 提供在苹果 silicon 芯片上高效运行 LLM 的方式。在模型包含 MLX 格式的时候,推荐使用苹果 silicon 芯片的 Mac 用户使用 MLX 引擎。